
Research
I am working on developing a principled and pracitcal data contribution/valuation estimation algorithms. With efficient data valuation algorithms, our goal is to assess the quality of individual data points for improving model performance and mitigating biases. Please see Publications for more.
OpenDataVal
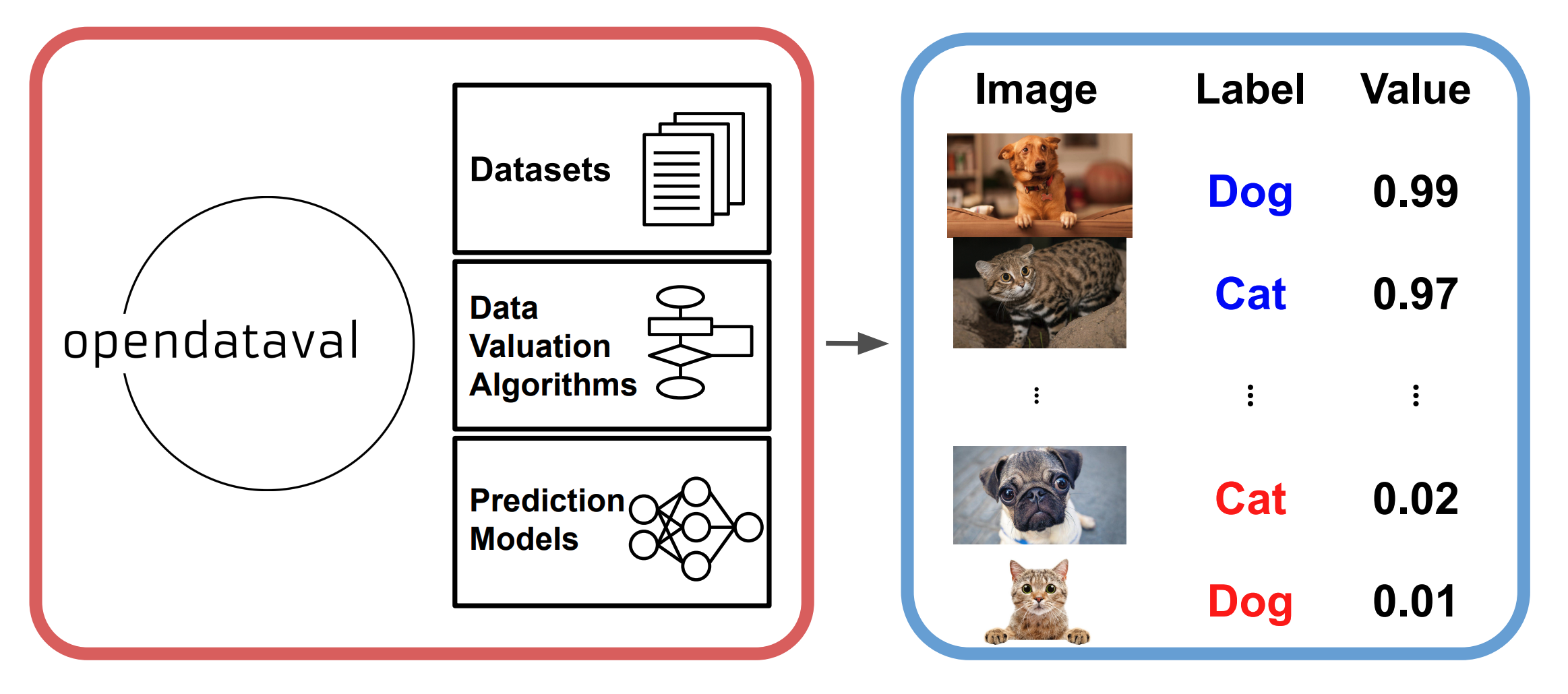
Numerous data valuation algorithms have been proposed in the literature, yet it is not clear which method is the most effective and appropriate to downstream machine learning tasks. For instance, what algorithm should we use for detecting anomalies in a given training dataset or interpreting model predictions? In our recent work, we introduce an open-source, easy-to-use and unified environment called OpenDataVal. It provides a benchmarking framework for various state-of-the-art data valuation algorithms including classic methods like the leave-one-out method and influence functions, as well as more modern Shapley-based methods and Data-OOB. You can compute the value of your data with a few lines of Python codes!!